
Pohon Keputusan atau dikenal dengan Decision Tree adalah salah satu metode klasifikasi yang menggunakan representasi suatu struktur pohon yang berisi alternatif-alternatif untuk pemecahan suatu masalah. Pohon ini juga menunjukkan faktor-faktor yang mempengaruhi hasil alternatif dari keputusan tersebut disertai dengan estimasi hasil akhir bila kita mengambil keputusan tersebut.
Proses klasifikasi biasanya dibagi menjadi dua fase ataupun karakteristik yaitu learning dan test. Pada fase learning, sebagian data yang telah diketahui kelas datanya digunakan untuk membentuk model perkiraan. Kemudian pada fase test, model yang sudah terbentuk diuji dengan data lainnya yang belum diketahui label / klasifikasinya. Berikut adalah gambaran struktur pohon keputusan yang memiliki 3 simpul node:

- Root node, merupakan node paling atas (akar) dimana pada node tidak ada input dan mempunyai output lebih dari satu. Simpul akar biasanya berupa atribut yang paling memiliki pengaruh terbesar pada suatu kelas tertentu.
- Internal node, merupakan node percabangan dimana pada internal node hanya terdapat satu input dan m mal 2 output (berderajat ≠ 0).
- Leaf node atau terminal node, merupakan node akhir dimana pada node hanya terdapat satu input dan tidak mempunyai output (berderajat 0).
Algoritma C4.5 merupakan algoritma yang berfungsi untuk klasifikasi atau segmentasi atau pengelompokan dan bersifat prediktif. Dasar dari algoritma C4.5 adalah pembentukan pohon keputusan (decision tree), dimana cabang-cabang pohon keputusan merupakan pertanyaan klasifikasi dan daun-daunnya merupakan kelas atau segmennya. Secara umum algoritma C4.5 untuk membangun Decision Tree dilakukan dengan beberapa tahapan sebagai berikut:
- Pilih atribut sebagai akar.
- Buat cabang untuk tiap-tiap nilai.
- Buat kasus dalam cabang.
- Ulangi proses untuk setiap cabang sampai semua kasus pada cabang memiliki kelas yang sama.
Dalam algoritma C4.5 pemilihan atribut yang akan diproses menggunakan information gain. Untuk memilih atribut sebagai akar, didasarkan pada nilai gain tertinggi dari nilai atribut-atribut yang ada. Jika di dalam cabang satu decision tree anggotanya berasal dari satu kelas maka cabang ini disebut pure. Jadi dalam memilih atribut untuk memecah objek dalam beberapa kelas harus dipilih atribut yang menghasilkan information gain paling besar. Ukuran information gain digunakan untuk memilih atribut uji pada setiap node di dalam tree. Ukuran ini digunakan untuk memilih atribut atau node pada pohon. Atribut dengan nilai information gain tertinggi dan bersih akan dipilih sebagai parent bagi node selanjutnya.
Untuk menghitung nilai gain, maka terlebih dahulu perlu menghitung nilai Entropy. Entropy merupakan distribusi probabilitas dalam teori informasi dan diadopsi kedalam algoritma C4.5 untuk mengukur tingkat homogenitas distribusi kelas dari sebuah himpunan (dataset). Sebagai ilustrasi, semakin tingkat entropy dari sebuah dataset maka semakin homogen distribusi kelas pada dataset tersebut.
Dalam postingan ini saya akan memberikan contoh perhitungan klasifikasi menggunakan algoritma decision tree C4.5.
Contoh kasus :
Berikut adalah contoh sebuah data yang digunakan untuk menentukan keputusan seseorang untuk bermain tennis atau tidak, beberapa variabel yang menentukan diantaranya adalah outlook (cuaca), temperature (suhu), humidity (kelembapan), dan windy (angin)
No
|
Outlook
|
Temperature
|
Humidity
|
Windy
|
Play
|
1
|
Sunny
|
Hot
|
High
|
FALSE
|
No
|
2
|
Sunny
|
Hot
|
High
|
TRUE
|
No
|
3
|
Cloudy
|
Hot
|
High
|
FALSE
|
Yes
|
4
|
Rainy
|
Mild
|
High
|
FALSE
|
Yes
|
5
|
Rainy
|
Cool
|
Normal
|
FALSE
|
Yes
|
6
|
Rainy
|
Cool
|
Normal
|
TRUE
|
Yes
|
7
|
Cloudy
|
Cool
|
Normal
|
TRUE
|
Yes
|
8
|
Sunny
|
Mild
|
High
|
FALSE
|
No
|
9
|
Sunny
|
Cool
|
Normal
|
FALSE
|
Yes
|
10
|
Rainy
|
Mild
|
Normal
|
FALSE
|
Yes
|
11
|
Sunny
|
Mild
|
Normal
|
TRUE
|
Yes
|
12
|
Cloudy
|
Mild
|
High
|
TRUE
|
Yes
|
13
|
Cloudy
|
Hot
|
Normal
|
FALSE
|
Yes
|
14
|
Rainy
|
Mild
|
High
|
TRUE
|
No
|
Berdasarkan data diatas, akan dilakukan proses pembuatan model / pola, yang kemudian digunakan memprediksi data baru yang belum memiliki label / klasifikasi. Adapun tahap perhitungannya adalah sebagai berikut :
Hitung gain dari masing-masing atribut (Outlook, Temperature, Himidity, Windy) kemudian bandingkan mana yang paling besar, itulah yang menjadi akar (root node). Cara menghitung gain, terlebih dahulu hitung nilai entropy dari masing-masing kategori dalam setiap atribut menggunakan rumus berikut :
Hitung gain dari masing-masing atribut (Outlook, Temperature, Himidity, Windy) kemudian bandingkan mana yang paling besar, itulah yang menjadi akar (root node). Cara menghitung gain, terlebih dahulu hitung nilai entropy dari masing-masing kategori dalam setiap atribut menggunakan rumus berikut :


Dimana :
S = Himpunan kasus
n = Jumlah partisi S
pi = Probabilitas yang didapat dari (Ya/Tidak) dibagi total kasus
Hitung nilai gain dengan menggunakan rumus berikut :

Dimana :
S = Himpunan kasus
A = Atribut
N = Jumlah partisi atribut A
|Si| = Jumlah kasus pada partisi ke-i
|S| = Jumlah kasus dalam S
Hitung jumlah kasus :
- Total data(S) = 14
- Jumlah kasus “No" (S1) =4
- Jumlah kasus “Yes" (S2)=10



Outlook, didalamnya terdapat partisi cloudy, rainy, dan sunny, hitung jumlah masing-masing partisinya, dan dari masing-masing partisi hitung juga berapa jumlah kasus dari setiap keputusan (Yes dan No)
| Atribut | Partisi | Kasus (S) | No (S1) | Yes (S2) |
| Outlook | Cloudy | 4 | 0 | 4 |
| Rainy | 5 | 1 | 4 | |
| Sunny | 5 | 3 | 2 |
Nilai entropy pada masing-masing partisi :



Nilai gain atribut outlook :



| Atribut | Value | Kasus (S) | No (S1) | Yes (S2) |
| Temperature | Hot | 4 | 2 | 2 |
| Mild | 6 | 2 | 4 | |
| Cool | 4 | 0 | 4 |
Nilai entropy pada masing-masing partisi :



Nilai gain atribut temperature :


Humidity, didalamnya terdapat high dan normal, hitung jumlah masing-masing partisinya, dan dari masing-masing partisi hitung juga berapa jumlah kasus dari setiap keputusan (Yes dan No)
| Atribut | Value | Kasus (S) | No (S1) | Yes (S2) |
| Humidity | High | 7 | 4 | 3 |
| Normal | 7 | 0 | 7 |
Nilai entropy pada masing-masing partisi :


Nilai gain atribut humidity :


Windy, didalamnya terdapat FALSE dan TRUE, hitung jumlah masing-masing partisinya, dan dari masing-masing partisi hitung juga berapa jumlah kasus dari setiap keputusan (Yes dan No)
| Atribut | Value | Kasus (S) | No (S1) | Yes (S2) |
| Windy | FALSE | 8 | 2 | 6 |
| TRUE | 6 | 2 | 4 |
Nilai entropy pada masing-masing partisi :

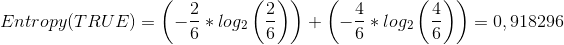
Nilai gain atribut windy :


Node
|
Atribut
|
Value
|
Kasus (S)
|
No (S1)
|
Yes (S2)
|
Entropy
|
Gain
|
1
|
Total
|
14
|
4
|
10
|
0,8631206
| ||
Outlook
|
0,258521
| ||||||
Cloudy
|
4
|
0
|
4
|
0
| |||
Rainy
|
5
|
1
|
4
|
0,7219281
| |||
Sunny
|
5
|
3
|
2
|
0,9709506
| |||
Temperature
|
0,183851
| ||||||
Hot
|
4
|
2
|
2
|
1
| |||
Mild
|
6
|
2
|
4
|
0,9182958
| |||
Cool
|
4
|
0
|
4
|
0
| |||
Humidity
|
0,370507
| ||||||
High
|
7
|
4
|
3
|
0,9852281
| |||
Normal
|
7
|
0
|
7
|
0
| |||
Windy
|
0,005978
| ||||||
FALSE
|
8
|
2
|
6
|
0,8112781
| |||
TRUE
|
6
|
2
|
4
|
0,9182958
|
Berdasarkan hasil perhitungan nilai gain tersebut, kemudian pilih nilai gain terbesar yang kemudian digunakan sebagai root node (akar) dari pohon keputusan, diketahui nilai gain terbesar adalah humidity, yakni sebesar 0,370507, sehingga atribut Humidity digunakan sebagai root.
Kemudian buat cabang sesuai banyaknya partisi. Pada atribut humidity terdapat dua partisi yakni High dan Normal, sehingga dari root humidity akan dibentuk dua cabang High dan Normal.
Atribut
|
Value
|
Kasus (S)
|
No (S1)
|
Yes (S2)
|
Humidity
| ||||
High
|
7
|
4
|
3
| |
Normal
|
7
|
0
|
7
|

Dari masing-masing cabang, perhatikan partisi yang memiliki kasus sama dengan 0. Dari data diatas, diketahui bahwa partisi normal memiliki nilai 0 pada kasus No, sehingga dapat dipastikan untuk humidity normal semuanya akan menghasilkan label Yes, maka pohon keputusan dapat dibuat sebagai berikut:

Sedangkan untuk partisi High, masih terdapat dua keputusan antara Yes dan No, sehingga apabila terdapat kasus seperti diatas, maka kita perlu melihat atribut yang lain, pada cabang high harus berisi atribut, oleh karena itu maka dilakukan proses pencarian node berikutnya, dengan menggunakan data yang telah di reduksi, yakni dengan melakukan filter Humidity = High, seperti berikut:
No
|
Outlook
|
Temperature
|
Humidity
|
Windy
|
Play
|
1
|
Sunny
|
Hot
|
High
|
FALSE
|
No
|
2
|
Sunny
|
Hot
|
High
|
TRUE
|
No
|
3
|
Cloudy
|
Hot
|
High
|
FALSE
|
Yes
|
4
|
Rainy
|
Mild
|
High
|
FALSE
|
Yes
|
5
|
Sunny
|
Mild
|
High
|
FALSE
|
No
|
6
|
Cloudy
|
Mild
|
High
|
TRUE
|
Yes
|
7
|
Rainy
|
Mild
|
High
|
TRUE
|
No
|
Adapun atribut yang perlu dihitung adalah Outlook, Temperature dan Windy, sementara untuk atribut Humidity tidak perlu dihitung kembali karena telah menjadi node. Hitung jumlah Entropy dan Gain dari masing-masing atribut seperti cara sebelumnya, dengan jumlah kasus yang baru (telah direduksi dari sebelumnya), sehingga diperoleh data hasil perhitungan untuk node 2 adalah sebagai berikut:
Node
|
Atribut
|
Value
|
Kasus (S)
|
No (S1)
|
Yes (S2)
|
Entropy
|
Gain
|
2
|
Total
|
7
|
4
|
3
|
0,9852281
| ||
Outlook
|
0,69951
| ||||||
Cloudy
|
2
|
0
|
2
|
0
| |||
Rainy
|
2
|
1
|
1
|
1
| |||
Sunny
|
3
|
3
|
0
|
0
| |||
Temperature
|
0,02024
| ||||||
Hot
|
3
|
2
|
1
|
0,9182958
| |||
Mild
|
4
|
2
|
2
|
1
| |||
Cool
|
0
|
0
|
0
|
0
| |||
Windy
|
0,02024
| ||||||
FALSE
|
4
|
2
|
2
|
1
| |||
TRUE
|
3
|
2
|
1
|
0,9182958
|
Diperoleh nilai gain terbesar adalah Outlook yakni 0,69951, sehingga dapat dibuat pohon keputusan untuk cabang High dari humidity diisi dengan atribut Outlook, kemudian dari outlook terdapat 3 partisi yakni Cloudy, Rainy dan Sunny.
Atribut
|
Value
|
Kasus (S)
|
No (S1)
|
Yes (S2)
|
Outlook
| ||||
Cloudy
|
2
|
0
|
2
| |
Rainy
|
2
|
1
|
1
| |
Sunny
|
3
|
3
|
0
|

Perhatikan nilai yang jumlah kasusnya 0, berdasarkan tabel diketahui Kasus "No" pada cloudy adalah 0, dan kasus "Yes" pada sunny juga sama dengan 0, sementara untuk rainy terdapat 2 keputusan sehingga pohon keputusannya dapat dibuat seperti berikut:

Lakukan ulang seperti langkah sebelumnya untuk mengetahui atribut berikutnya dengan kondisi Outlook = Rainy berdasarkan tabel yang baru (hasil filter dari tabel sebelumnya)
No
|
Outlook
|
Temperature
|
Windy
|
Play
|
1
|
Rainy
|
Mild
|
FALSE
|
Yes
|
2
|
Rainy
|
Mild
|
TRUE
|
No
|
Dengan cara / proses yang sama seperti sebelumnya diperoleh tabel untuk node ke-3 sebagai berikut:
Node
|
Atribut
|
Value
|
Kasus (S)
|
No (S1)
|
Yes (S2)
|
Entropy
|
Gain
|
3
|
Total
|
2
|
1
|
1
|
1
| ||
Temperature
|
0
| ||||||
Hot
|
0
|
0
|
0
|
0
| |||
Mild
|
2
|
1
|
1
|
1
| |||
Cool
|
0
|
0
|
0
|
0
| |||
Windy
|
1
| ||||||
FALSE
|
1
|
0
|
1
|
0
| |||
TRUE
|
1
|
1
|
0
|
0
|
Diperoleh nilai gain terbesar adalah windy =1, sehingga atribut untuk node berikutnya adalah windy, dan hasil akhir pohon keputusan adalah sebagai berikut:

Perhitungan di atas merupakan proses training, yakni pembuatan model / pola, yang kemudian diaplikasikan untuk data / kasus baru yang belum diketahui label / klasifikasinya. Untuk mengaplikasikan model diatas, kita dapat mencoba pada data baru yang belum diketahui keputusannya, misal seperti berikut :
No
|
Outlook
|
Temperature
|
Humidity
|
Windy
|
Play
|
1
|
Rainy
|
Hot
|
High
|
TRUE
|
?
|
Berdasarkan data di atas, untuk mendapatkan hasil keputusan apakah harus bermain tennis atau tidak, maka dapat dilihat berdasarkan model yang telah terbentuk sebelumnya, yakni :
Jika Humidity = High dan Outlook = Rainy dan Windy = TRUE maka Play = No
Sehingga hasil klasifikasinya adalah No
Sekian, semoga postingan ini bermanfaat, terimakasih

 dan Sampel Saling Bebas (Independent Sample t-test)")
![[Pembahasan] Analisis Regresi dengan Variabel Dummy dengan SPSS](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiUznT5C5FkWyLv3z4su2wvms3lPC07J9NvyzvYSxw6bL_1ZN7AeKVEx6LjsEU_Y9xzTztAtdqIw9ZBDptr4z17aiRsPfarkS1jdVqSYDfD91EHoEiJFYP4NHAEcJqMFjQJD4lepk4QfVdj/s72-c/Untitled-1.jpg "[Pembahasan] Analisis Regresi dengan Variabel Dummy dengan SPSS")







2 comments
Write commentsMet siang Gan, boleh minta file perhitungan dengan excel nya !?!
ReplyTerimakaish
:) :( hihi :-) :D =D :-d ;( ;-( @-) :P :o -_- (o) :p :-? (p) :-s (m) 8-) :-t :-b b-( :-# =p~ $-) (y) (f) x-) (k) (h) cheer lol rock angry @@ :ng pin poop :* :v 100