
Tentu saja anda akan bosan dengan prolog yang terlalu panjang, jadi langsung saja saya akan berbagi kode beserta penjelasan singkat, berikut langkah-langkahnya :
Pertama, kita perlu menginstall beberapa packages pendukung yang akan digunakan, selanjutnya memanggil packages tersebut :
library("rvest")
library("dplyr")
library("stringr")
library("readr")
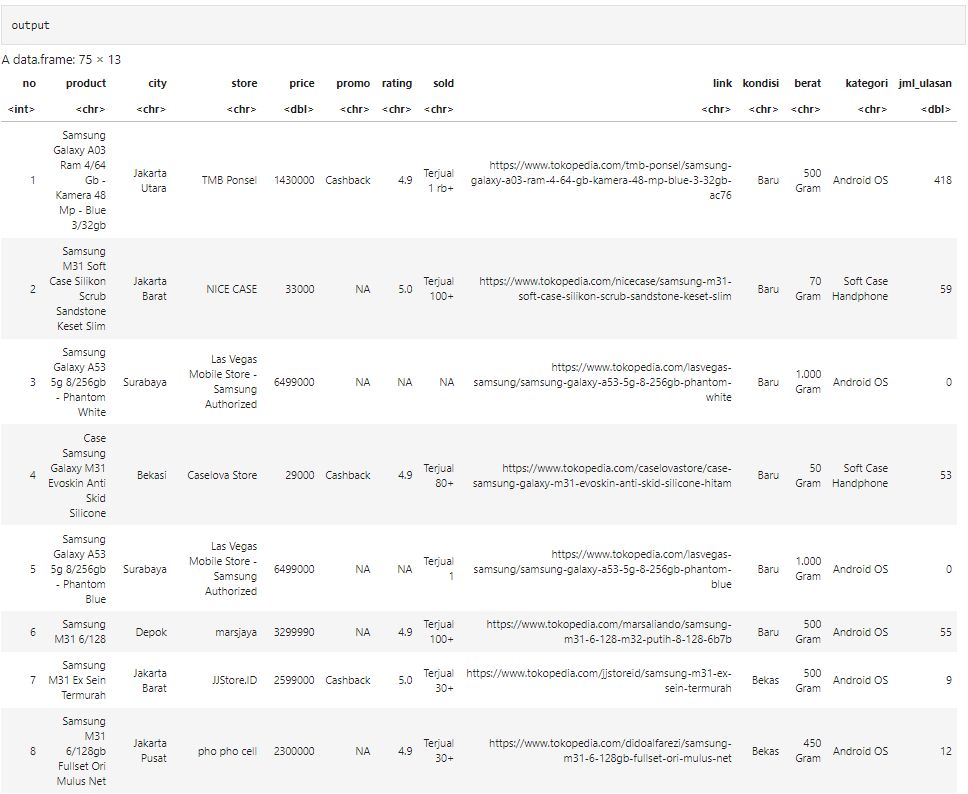
Adapun beberapa informasi yang akan saya tarik datanya adalah nama produk, harga, kota penjual, nama toko, link produk, jenis promo, rating, jumlah produk terjual. Kemudian pada setiap link produk yang telah saya tarik, akan dilakukan proses scraping untuk mendapatkan beberapa detail informasi seperti kondisi barang, berat barang, kategori dan jumlah ulasan. Tentu saja proses ini akan cukup memakan waktu, karena saya perlu melakukan looping pada setiap satu produk, ditambah saya perlu melakukan looping pada halaman website.
Berikut adalah function yang telah saya buat :
scrape<-function(keywords,page)
{
key = gsub(" ","%20",keywords)
all_data<-data.frame()
for (x in 1:page)
{
url<-paste("https://www.tokopedia.com/search?navsource=home&page=",x,"&q=",key,sep="")
readUrl<-read_html(url)
product<- readUrl %>%
html_nodes('div[data-testid=spnSRPProdName]') %>%
html_text()
price<- readUrl %>%
html_nodes('div[data-testid=spnSRPProdPrice]')%>%
html_text()
city<- readUrl %>%
html_nodes('span[data-testid=spnSRPProdTabShopLoc]')%>%
html_text()
store<-c()
att<-readUrl %>%
html_nodes('span[class="css-1kdc32b flip"]') %>%
html_text() %>%
str_replace_all("'","'")
count = 1
for(i in att)
{
if(count %% 2 == 0)
{
store<-c(store,i)
}
count = count + 1
}
link<-readUrl%>%
html_nodes('div[class="css-12sieg3"]') %>%
html_nodes('div[class="css-y5gcsw"]') %>%
html_nodes('div[class="css-5fmc3z"]') %>%
html_nodes('div[class="css-qa82pd"]') %>%
html_nodes('div[class="css-1c4umxf"]') %>%
html_nodes('div[class="pcv3__container css-gfx8z3"]') %>%
html_nodes('div[class="css-zimbi"]') %>%
html_nodes('a[href]') %>%
html_attr('href') %>%
str_remove(".*www.tokopedia.com") %>%
str_replace_all(c("%2F"="/","%3D"="=")) %>%
paste0("https://www.tokopedia.com",.,sep="") %>%
str_remove("%3F.*") %>%
str_remove("\\?.*")
info<-data.frame()
count <- 1
for(index in link)
{
kondisi<-read_html(index) %>%
html_nodes('ul[data-testid="lblPDPInfoProduk"] [class="css-1dmo88g"]') %>%
html_text() %>% strsplit(split = ": ")
kondisi<-kondisi[grep('Kondisi',kondisi)][[1]][2]
berat<-read_html(index) %>%
html_nodes('ul[data-testid="lblPDPInfoProduk"] [class="css-1dmo88g"]') %>%
html_text() %>% strsplit(split = ": ")
berat<-berat[grep('Berat',berat)][[1]][2]
kategori<-read_html(index)%>%
html_nodes('ul[data-testid="lblPDPInfoProduk"] [class="css-1dmo88g"]') %>%
html_text() %>% strsplit(split = ": ")
kategori<-kategori[grep('Kategori',kategori)][[1]][2]
jml_ulasan<-read_html(index)%>%
html_nodes('div,span[data-testid="lblPDPDetailProductRatingCounter"]') %>%
html_nodes('.css-ddjk3l') %>%
html_text() %>% str_remove('.css-1s46cvt.*') %>%
parse_number()
count = count + 1
info<-rbind(info,data.frame(kondisi,berat,kategori,jml_ulasan))
}
promo<-readUrl%>%
html_nodes('div[class="css-12sieg3"]') %>%
html_nodes('div[class="css-y5gcsw"]') %>%
html_nodes('div[class="css-5fmc3z"]') %>%
html_nodes('div[class="css-qa82pd"]') %>%
html_nodes('div[class="css-1c4umxf"]') %>%
html_nodes('div[class="pcv3__container css-gfx8z3"]') %>%
html_nodes('div[class="css-974ipl"]') %>%
html_nodes('a[class="pcv3__info-content css-gwkf0u"]') %>%
lapply(. %>% html_nodes('[class="css-tolj34"]') %>% html_text() %>%
ifelse(identical(., character(0)), NA, .)) %>% unlist
rating<-readUrl%>%
html_nodes('div[class="css-12sieg3"]') %>%
html_nodes('div[class="css-y5gcsw"]') %>%
html_nodes('div[class="css-5fmc3z"]') %>%
html_nodes('div[class="css-qa82pd"]') %>%
html_nodes('div[class="css-1c4umxf"]') %>%
html_nodes('div[class="pcv3__container css-gfx8z3"]') %>%
html_nodes('div[class="css-974ipl"]') %>%
html_nodes('a[class="pcv3__info-content css-gwkf0u"]') %>%
lapply(. %>% html_nodes('[class="css-t70v7i"]') %>% html_text() %>%
ifelse(identical(., character(0)), NA, .)) %>% unlist
sold<-readUrl%>%
html_nodes('div[class="css-12sieg3"]') %>%
html_nodes('div[class="css-y5gcsw"]') %>%
html_nodes('div[class="css-5fmc3z"]') %>%
html_nodes('div[class="css-qa82pd"]') %>%
html_nodes('div[class="css-1c4umxf"]') %>%
html_nodes('div[class="pcv3__container css-gfx8z3"]') %>%
html_nodes('div[class="css-974ipl"]') %>%
html_nodes('a[class="pcv3__info-content css-gwkf0u"]') %>%
lapply(. %>% html_nodes('[class="css-1duhs3e"]') %>% html_text() %>%
ifelse(identical(., character(0)), NA, .)) %>% unlist
all_data<-rbind(all_data,data.frame(product,city,store,price,promo,rating,sold,link,info))
}
all_data<- all_data %>%
mutate(no=1:nrow(all_data), .before=product) %>%
mutate(price = str_replace(price, "Rp", "")) %>%
mutate(price = as.numeric(gsub(",", ".", gsub("\\.", "", price)))) %>%
mutate(product = str_to_title(product)) %>%
mutate(product = gsub(" "," ",product))
return(all_data)
}
Function tersebut berisi parameter keyword dan jumlah halaman yang akan ditarik datanya.
Dalam kasus ini saya akan menggunakan function tersebut untuk melakukan scraping data dengan keyword "Samsung M31" dan jumlah halaman sebanyak 5 halaman.
#scrape('input keywords',input total page number)
output<-scrape('Samsung M31',5)
Dan berikut output dari data yang berhasil saya tarik :
Demikian secuil ilmu yang bisa saya bagikan, silahkan tinggalkan komentar dan follow blog ini agar lebih semangat memposting konten konten bermanfaat seputar ilmu data.
Terima kasih
Salam Scientist

 dan Sampel Saling Bebas (Independent Sample t-test)")
![[Pembahasan] Analisis Regresi dengan Variabel Dummy dengan SPSS](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiUznT5C5FkWyLv3z4su2wvms3lPC07J9NvyzvYSxw6bL_1ZN7AeKVEx6LjsEU_Y9xzTztAtdqIw9ZBDptr4z17aiRsPfarkS1jdVqSYDfD91EHoEiJFYP4NHAEcJqMFjQJD4lepk4QfVdj/s72-c/Untitled-1.jpg "[Pembahasan] Analisis Regresi dengan Variabel Dummy dengan SPSS")







:) :( hihi :-) :D =D :-d ;( ;-( @-) :P :o -_- (o) :p :-? (p) :-s (m) 8-) :-t :-b b-( :-# =p~ $-) (y) (f) x-) (k) (h) cheer lol rock angry @@ :ng pin poop :* :v 100